DMA全称直接内存访问。
简单地说,DMA是一种允许计算机外部设备(例如:硬盘、网卡、声卡、GPU等)直接与主存进行数据读写,而无需中央处理器持续参与的技术。
在没有DMA的时代,这种数据转移需要CPU作为"中间人"。
1.为什么需要DMA?—— PIO模式的弊端
在DMA出现之前,数据通过PIO来进行传输。我们通过一个例子来看PIO的问题:
场景:网卡接收一个数据包,并存放到内存中。
PIO模式:
网卡收到数据,存放到自己的内部缓冲区。
网卡向CPU发出一个中断信号。
CPU响应中断,执行网卡驱动程序的代码。
驱动程序指令CPU,从网卡的I/O端口一个字节一个字节(或一个字一个字) 地读取数据。
CPU每读一个字节,就把它写入到内存的指定位置。
重复步骤4和5,直到所有数据转移完毕。
CPU继续执行被中断前的任务。
PIO的致命缺点:
在整个数据转移过程中,CPU被完全占用,只能做“搬运工”这种简单重复的工作。如果传输一个几KB的网络数据包,CPU就要执行成千上万条指令来搬运数据,这造成了巨大的CPU资源浪费。在传输大块数据(如磁盘读写)时,整个系统几乎会停滞。
2. DMA是如何工作的?
DMA控制器是一个专门的硬件芯片,它可以看作是CPU的一个“智能代理”,专门负责管理数据搬运。
DMA工作流程(以网卡接收数据为例):
初始化:
操作系统(驱动程序)在内存中分配一块缓冲区。
驱动程序将这块缓冲区的起始地址和大小告诉DMA控制器和网卡。
驱动程序启用DMA传输。
数据传输:
网卡收到数据包。
网卡不打扰CPU,而是直接通知DMA控制器。
DMA控制器向内存控制器发出请求,获得总线控制权。
DMA控制器指挥数据,直接从网卡通过系统总线写入到内存的指定缓冲区中。在整个过程中,CPU可以自由地执行其他任务。
完成通知:
当整个数据包传输完成后,DMA控制器会向CPU发出一个中断信号。
CPU收到这个中断后,才知道数据已经准备好了。此时,驱动程序才会介入,处理这个完整的数据包(例如,将其送入协议栈)。
这个过程可以类比为:
PIO模式: 就像你(CPU)亲自一箱一箱地把货物从卡车上搬进仓库。
DMA模式: 你雇佣了一个搬运队(DMA控制器),你只需要告诉搬运队“把货搬到仓库的A区”,然后你就可以去忙别的事了。搬运队干完活后,过来跟你说“老板,搬完了”,你再去检查一下。
3. DMA的优势
解放CPU: 这是最核心的优势。CPU从繁重的数据搬运工作中解脱出来,可以更高效地处理计算任务,显著提高了系统的整体性能和并发能力。
提高数据传输速率: DMA控制器是为数据搬运而专门优化的硬件,通常能实现比PIO模式更高的吞吐量。
降低功耗: CPU不需要为每个字节的传输而忙碌,可以更长时间地处于空闲或低功耗状态。
4. DMA与其他技术的关系
DMA与内核旁路:
内核旁路技术(如DPDK)极大地依赖DMA。它让网卡通过DMA,直接将数据包写入到应用程序在用户空间预先分配好的内存中,完全绕过了内核的协议栈,实现了真正的“零拷贝”I/O。没有DMA,内核旁路的性能优势将大打折扣。
DMA与零拷贝:
“零拷贝”技术的目标是减少或消除数据在内存中的不必要的复制。DMA是实现零拷贝的基石。例如,当网卡通过DMA将数据直接写入内存,然后应用程序直接从该内存读取,这就避免了一次从内核空间到用户空间的拷贝。
DMA与RDMA:
RDMA可以看作是DMA理念在网络领域的延伸。普通的DMA是在单机内部,让设备直接访问本地内存。而RDMA则允许一台机器的网卡直接访问另一台机器的内存,再次绕过了对方主机的CPU和操作系统内核,广泛应用于高性能计算和数据中心。
PIO全称编程输入/输出。
是一种 早期、基础的计算机数据交换方式,指的是中央处理器直接通过I/O指令,来控制外部设备并与他们进行数据传递。
在PIO模式下,数据在外部设备(如硬盘、网卡等)和内存之间的内一次移动,都需要CPU亲自介入和参与。CPU是整个数据传输过程中的唯一指挥官和搬运工。
PIO模式工作原理
让我们以 从硬盘读取数据到内存 这个经典场景为例,详细拆解 PIO 模式的工作流程:
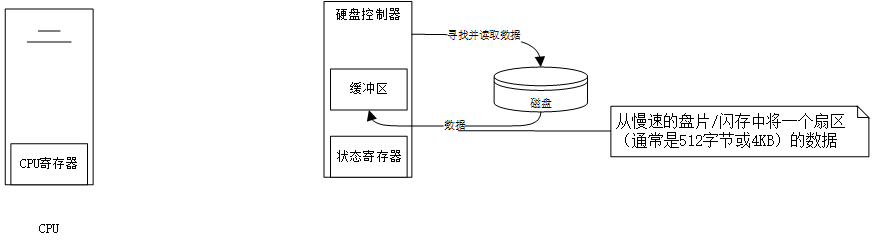
1.发起请求:CPU 执行驱动程序代码,向硬盘控制器发出“读取数据”的命令,并告知要读取数据的地址和长度。

2.设备准备:硬盘控制器收到命令后,开始从盘片寻找并读取数据到其内部的缓冲区。这个过程需要一些时间(寻道时间和旋转延迟)。
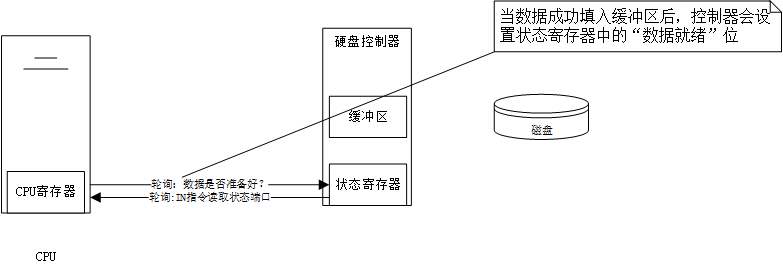
3.状态轮询:CPU 持续不断地查询硬盘控制器的状态寄存器,检查数据是否已经准备好。这是一种“忙等待”,CPU 在此期间不能做其他事。
4.数据搬运:
一旦 CPU 检测到数据已准备好,它就会执行一条 IN 指令,从硬盘的数据端口读取一个字节(或一个字)的数据到 CPU 的寄存器(如 AX 寄存器)中。
紧接着,CPU 再执行一条 MOV 指令,将这个字节(或字)从寄存器写入到内存的指定位置。
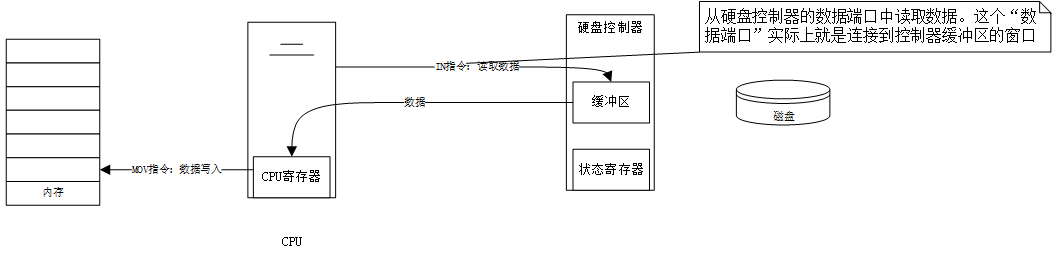
5.循环往复:步骤 3 和 4 会一直重复,直到所有数据都被一点一点地、像蚂蚁搬家一样从硬盘搬运到内存中。
6.完成:整个数据块传输完毕,CPU 可以继续执行其他任务。
内核旁路
简单来说,内核旁路是一种允许用户空间的应用程序直接与硬件设备(最常见的是网卡)进行数据交互的技术,而无需将数据包通过操作系统内核进行传递。
为了更好地理解,我们先看看传统的数据处理流程:
传统网络数据包处理路径:
网卡收到数据包。
网卡通过DMA将数据包放到内核缓冲区(Ring Buffer)。
网卡向CPU发出中断信号,告诉内核“有数据来了”。
内核的网卡驱动处理中断,将数据包从Ring Buffer拷贝到内核协议栈(如TCP/IP栈)进行解析。
协议栈处理完后,将有效数据(Payload)从内核空间拷贝到用户空间的应用缓冲区。
应用程序终于可以读取并处理这些数据。
这个过程涉及两次关键的数据拷贝(内核缓冲区->协议栈,内核空间->用户空间)和一次中断处理。这些操作在需要高吞吐、低延迟的场景下,会成为巨大的性能瓶颈。
内核旁路路径:
应用程序在启动时,通过一个特权的“加载器”或驱动,在网卡和用户空间之间建立一条直接的数据通道。
网卡收到数据包后,通过DMA直接将其放入应用程序在用户空间预先分配好的内存缓冲区中。
应用程序通过轮询的方式,直接检查这些缓冲区,发现新数据后立即处理。
整个过程没有内核参与,没有数据拷贝,也没有中断。
1. 为什么需要内核旁路?—— 核心优势
内核旁路技术主要为了解决以下传统方式的性能瓶颈:
消除上下文切换: 传统方式中,每次系统调用(如
read,write)都需要从用户态切换到内核态,处理完再切换回来,这个过程(上下文切换)开销很大。内核旁路让应用程序常驻用户态,避免了这种切换。减少/消除数据拷贝: 如上所述,传统路径有多次数据拷贝。内存拷贝是CPU密集型操作,会消耗大量CPU周期。内核旁路实现了“零拷贝”。
避免中断开销: 对于高流量场景,每次数据包都触发中断会使得CPU应接不暇,效率低下。内核旁路采用轮询模式,CPU主动去检查是否有新数据,虽然会占用一个CPU核心(忙等待),但在高负载下延迟更低、更可预测。
降低延迟和提高吞吐量: 综合以上所有优点,内核旁路技术能够将网络延迟从微秒级别降低到纳秒级别,并大幅提升每秒能处理的数据包数量。
2. 内核旁路是如何实现的?
内核旁路并非完全不需要操作系统。它的建立通常需要一个特权代理(比如一个内核驱动或一个具有特权的用户态进程)来帮忙设置初始环境。
通用实现步骤:
特权初始化: 一个具有特权的管理程序(例如,一个特定的内核驱动如
uio或vfio-pci)被加载,它负责将网络设备(网卡)映射到用户空间。内存注册: 应用程序分配一大块内存区域(通常是巨页,以减少TLB Miss),并将其“注册”或“锁定”在物理内存中(防止被换出),然后将其地址和大小告知网卡。
建立队列: 应用程序和网卡之间建立直接通信的队列,例如发送队列和接收队列。网卡知道该往哪个内存地址放数据,应用程序也知道该从哪个地址取数据。
轮询模式驱动: 应用程序链接一个用户态的轮询模式驱动库。这个库提供API,让应用程序能够直接读写网卡的寄存器和管理队列,并通过持续轮询队列描述符的状态来接收和发送数据。
主流的内核旁路技术框架/库:
DPDK: 由Intel主导的开源项目,是目前最流行、最成熟的方案。它提供了一整套用户态库和驱动,支持多种网卡。
Solarflare EF_VI: Solarflare网卡提供的低延迟接口,被广泛应用于金融交易领域。
Mellanox RDMA/ROCE: 基于远程直接内存访问技术,不仅绕过了内核,甚至绕过了远程主机的CPU,直接访问内存。
Netmap: 一个轻量级的内核旁路框架,它的设计思想略有不同,它向用户空间暴露的是内核网络栈的“影子”,性能也非常高。
3. 内核旁路的挑战与缺点
没有完美的技术,内核旁路在带来性能提升的同时,也引入了新的复杂性:
独占硬件资源: 被旁路的网卡或网卡队列通常无法再被操作系统内核或其他应用程序使用。你需要为特定的应用专门分配硬件资源。
绕过内核网络栈: 这意味着你失去了内核提供的成熟、稳定的TCP/IP协议栈。你需要:
自己实现协议栈: 在用户空间实现一个高性能的TCP/IP栈(例如 DPDK 自带的
l3fwd或l2fwd示例)。这非常复杂。使用用户态协议栈库: 如
mTCP,F-Stack等,但它们可能功能不全或不够稳定。仅处理特定协议: 很多应用只处理UDP或自定义的L2/L3协议,以简化设计。
安全性考虑: 由于绕过了内核,你也绕过了内核内置的防火墙(如
iptables)、安全模块等。安全策略需要在应用程序自身或前端的专用设备上实现。开发复杂性: 使用DPDK等库进行开发,比使用标准的BSD Socket API要复杂得多,对开发者的要求更高。
CPU资源占用: 轮询模式会占满一个CPU核心,即使没有数据处理,它也在空转,这在低负载时是浪费的。现代技术(如DPDK的“中断+轮询”混合模式)正在努力缓解这个问题。
4. 主要应用场景
内核旁路技术主要用于那些对性能有极端要求的领域:
高频交易: 金融市场上,纳秒级的延迟优势都可能带来巨大利润。
电信核心网: 4G/5G基站、路由器、交换机等网络设备,需要处理海量数据包。
软件定义网络: 在SDN/NFV场景中,vSwitch(如OVS-DPDK)使用内核旁路来获得接近硬件的转发性能。
大型负载均衡器: 例如Cloudflare、Facebook等公司的边缘网关。
实时数据分析系统: 对网络流进行实时监控和分析的系统。